Enabling the detection of micro-pollutants, particle traces, and hazardous substances, our advanced analytical technologies support environmental monitoring and forensic investigations with accuracy, reliability, and expert application know-how.
Our advanced analytical solutions support pharmaceutical workflows from drug discovery to quality control. Delivering accurate characterization, impurity profiling, and stability testing, we help ensure data integrity and regulatory compliance.
Over time, instruments will wear, causing them not to run as smoothly or report results as accurately. Within this, part of the instruments can be replaced with new or refurbished spare parts, preventing downtime and keeping them working effectively.
Target Analysis’ repair services for GCs, HPLCs, mass spectrometers, and other lab instruments include warranty coverage, service agreements, and preventative maintenance. Whether you are seeking instrument repair or scheduling a service call for lab equipment repair.
Our experienced technicians will quickly restore your pump to top performance – regardless of its age. We offer comprehensive on-site support for vacuum components and systems, troubleshooting, maintenance, and repairs.
Target Analysis IQ/OQ/PQ procedures strictly follow good laboratory practices (GLP), which require that all laboratory instrumentation be inspected, cleaned, and maintained. We provide an independent and comprehensive testing service for Mass Spectrometry & Chromatography instruments to help you meet your regulatory and operational requirements and standards.
The philosophy behind our services is that we can support all the scientific instruments that we sell. Our technical department is trained and certified to offer a complete system service across multiple brands and models, including Mass Spectrometers (MS), Liquid Chromatographs (LC), Gas Chromatographs (GC), Autosamplers, Detectors & Peripherals
Remote support provides additional service through remote software to resolve instrument issues before a technician is dispatched. Our remote support team works with you via phone and software to remotely control your system to troubleshoot, repair or assist. This additional level of support allows for faster resolution of issues and ultimately reduces instrument downtime.
Application support is a service provided by our team that gives you a strategy and technique to quickly and confidently develop high-quality methods. You will learn a proven technique that will guide you step-by-step through the process of method development, applying principles that will make the process more efficient. Application support can take the form of a course, training, or development of an analytical method based on your real samples.
Omics technologies adopt a holistic view of the molecules that make up a cell, tissue, or organism. Target Analysis can provide unique solutions for bioinformatics services for proteomics and metabolomics workflows. Based on our experienced team members, we can readily meet the rigorous demands of various fields, such as life sciences, nutrition research, etc.
Customized training solutions from sample preparation to data analysis. Specially designed courses to meet today’s ever-increasing demands for analytical performance, productivity and ease of use!
Target Analysis was founded in 2013 by a team of experienced scientists and engineers.
Through the trust of our customers and partners, Target Analysis has managed to create a team with experienced and trained staff, which undertakes the installation of instruments, staff training, and after-sales support with spare parts, consumables, and certified reference materials. The company’s know-how is constantly expanding and is ready to take on any challenge to solve your analysis issues.
See how our customers are using Target Analysis’ products to transform their research and ultimately make discoveries that help change the way we see the future.
Bruker ProteoScape™ (BPS) is a GPU-powered platform delivering parallel computing capabilities and real-time database search results for bottom-up proteomics.
TIMScore provides the greatest number of PSM, peptide and protein identifications by enabling the CCS dimension for true 4D-Proteomics.
The PaSER search algorithm is run as normal, combined with comparison of the predicted and measured CCS values and calculating a TIMScore for the top 5 peptide candidates for each spectra. The TIMScore benefit is realized during the peptide-validation and False Discovery Rate (FDR) estimation steps. With TIMScore, and the extra CCS dimension, the peptide-candidates can be vectorized in 3 dimensions allowing a discriminate contoured plane to be applied to achieve the same 1% error.
Real-time results to inform you of current instrument and sample status
Analysis Time
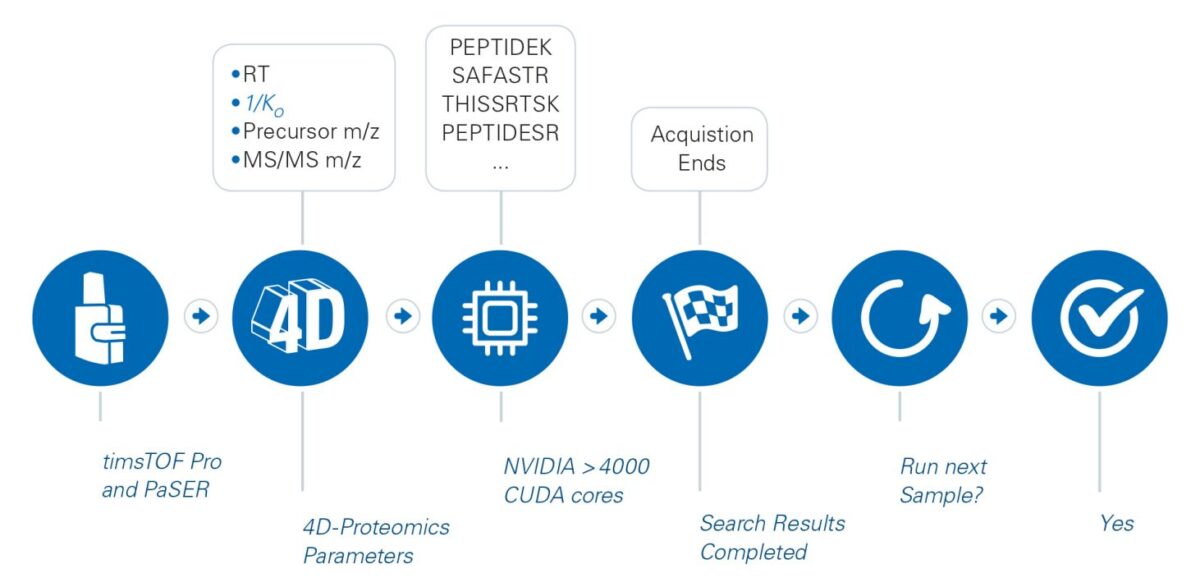
Database searches take time, eliminate this step with uncompromised search results as soon as the acquisition is complete.
Instrument Time
Be sure every minute counts, with PaSER you can be assured that your instrument time is spent in the most meaningful way.
Precious Samples
Save those precious samples! Whether they are single cell, clinical, SILAC or enriched PTMs; PaSER’s smarts will make sure they are not wasted.
Costs
Instrument time, reagents and sample preparation are costly. PaSER and Run & Done will save money because you are assured you are producing meaningful data.
Important Features to Consider
4D-Proteomics™ with real-time search results and smart acquisition
Break the data analysis bottleneck by integrating real-time database search and smart acquisition provided by PaSER
Universally available
All current and future timsTOF Pro and fleX platforms are PaSER accessible
4D-Proteomics™
CCS-enabled data is rich, even so real-time database search capabilities are a reality with PaSER including with PTMs like phosphorylation
Massive parallelization with GPU power
PaSER is GPU powered, provides massive compute power across thousands of CUDA cores
PaSER Data Review
View the intricate details of your data from the high level experimental information to a specific fragment ion spectrum of interest with confidence from the integrated viewer onboard of all PaSER boxes
Smarts
PaSER is smart, where a user defined qualification of proteins or peptides at the end of a sample acquisition determines the progression of your sample queue, this checks suitability, save precious samples, expensive consumables and instrument time
Benefits
Benefit from time and cost savings
No more worrying about injecting those precious samples.
No more worrying of wasted instrument time.
No more worrying about those samples with expensive reagents and sample prep, only to inject on a poor performing system.
No more waiting for the QC runs to determine system suitability.
No more waiting for search results during method development.
Applications
TIMScore™ – Machine Learning and CCS exploited for better FDR
TIMScore provides the greatest number of PSM, peptide and protein identifications by enabling the CCS dimension for true 4D-Proteomics.
The PaSER search algorithm is run as normal, combined with comparison of the predicted and measured CCS values and calculating a TIMScore for the top 5 peptide candidates for each spectra. The TIMScore benefit is realized during the peptide-validation and False Discovery Rate (FDR) estimation steps.
In a non CCS-enabled algorithm, only two dimensions can be utilized to estimate the FDR rate, and so a discriminate line is fit to a 1% error (Panel A) to distinguish forward and reverse peptide candidates. With TIMScore, and the extra CCS dimension, the peptide-candidates can be vectorized in 3 dimensions (Panel B) allowing a discriminate contoured plane to be applied to achieve the same 1% error. Applying a discriminate plane provides increased accuracy and precision, helping to validate formerly poorly scoring PSMs in the standard two dimensions.
dia-PASEF workflows streamlined on PaSER with TIMS DIA-NN
PaSER 2022 is capable of processing dia-PASEF workflows utilizing a customized version of the popular DIA-NN (DIA by Neural Networks) software from the Lilley, Rasler and Demichev labs. TIMS DIA-NN enables reliable, robust, and quantitatively accurate large-scale experiments. PaSER utilizes the same stream mechanism for dia-PASEF workflows, streaming in real-time MS and DIA frames from the acquisition PC to the PaSER box. These dia-PASEF data are processed and stored on the PaSER box. At the end of the acquisition a spectral library search is triggered, and the results recorded. TIMScore powered DDA search results can be easily utilized to build spectral libraries or spectral libraries can be imported from other popular tools. At the end of the project the users can trigger match-between-runs analysis to view a quantitative profile across projects. This provides users an integrated environment for PASEF and dia-PASEF data analysis.
Y-axis are counts and X-axis is total K562 peptide loaded on column in nanograms. The gradient length was 35 minutes, supporting 30 samples per day with all experiments performed on a timsTOF Pro 2.
Full-fledged database search in less than 5 ms
Blazing search speed with uncompromised search results.
A) Protein ID from replicate DDA runs of a human cell lysate using PaSER for real-time results and benchmarked against MaxQuant
B) Peptide ID from replicate DDA runs of a human cell lysate using PaSER for real-time results and benchmarked against MaxQuant
C) PaSER and MaxQuant identify 97% of the same proteins and nearly 90% of the same peptides.
PaSER provides consistent results obtained from the real-time search, identical to offline search of the same data. Since the database search algorithm is run on the GPU, the search times are negligible compared to CPU based searches.
In addition to real-time search the opportunity to search a larger space for specific applications, including including peptidome studies, becomes reality. PaSER benchmarked against the gold standard in DDA searches performs as good or better.
See what you have always been missing
TIMS Viz provides the powerful ability to view 4-D proteomics data like never seen before. The mobility separation and focusing upstream from the quadrapole and TOF result in the separation of isobaric and near isobaric species. Using other technologies and in the case of PTM enrichments and the analysis of complex samples it is common that co-eluting species that are isobaric or near isobaric in mass co-fragment. The timsTOF Pro/flex obviates this by first separating ions by their collisional cross section. The ability to visualize, search and sort on such events has never been available before. We term isobaric masses with different mobility values mobility offset mass aligned (MOMA), and TIMS Viz can tease such events out within complex runs. TIMS Viz allows you to set tolerances to your discretion while simultaneously overlaying both features and PSMs that were observed post database search. TIMS Viz enables you to view what you never knew was there before.
Related Products
No items found
Related Articles (Application Posts, Scientific Articles, etc.)